Many federal agencies struggle with a cumbersome legacy data infrastructure, excessively dispersed data, limited scientific tooling, and a reactive culture toward data analytics. In addition to these challenges, USDA FPAC’s workforce is limited in data science resources, lacks access to data tools, and has little training to analyze and extract insights from data.

To address these challenges, the agency is on a mission to transform and modernize its end-to-end data management platform, culture, processes, and tools. FPAC possesses large amounts of valuable real-time and historical data and has embarked on a journey to harness and maximize the power of this data in the service of a diverse set of stakeholders.
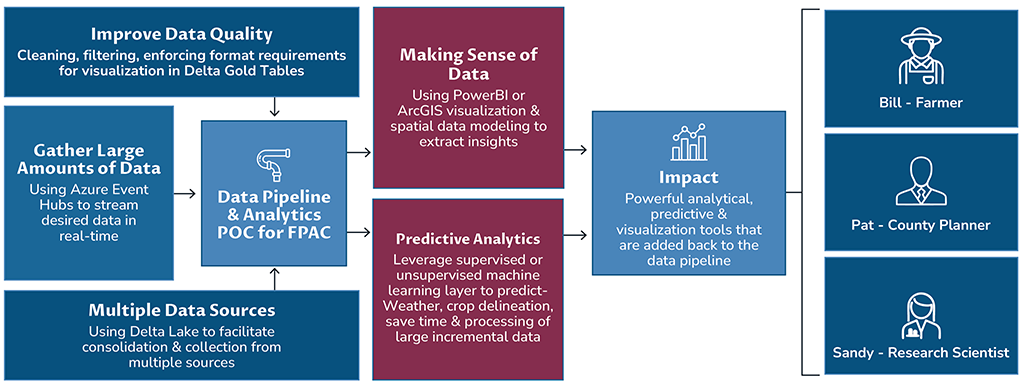
As a proof of concept (POC) for FPAC, Cadmus leveraged vSTART, an internal platform of out-of-the-box components, to build a custom data pipeline in a tight timeline. This POC consolidates disparate data sources, consumes batch and streaming data, uses Delta Lake layers to improve quality and aggregation challenges, and streamlines the ability to create dashboards and visualizations of varying complexity for multiple use cases. By leveraging vSTART, Cadmus was able to quickly and efficiently build a robust data pipeline that can handle large volumes of data and provide valuable insights for various business needs.
“The POC approach followed a consistent Cadmus strategy of applying Agile and UCD principles throughout the product lifecycle. This approach ensured that we focused on the customer experience while satisfying business objectives. By leveraging reusable components from vSTART, we designed and built the minimum viable product (MVP) within weeks,” said Khanh Armstrong, Cadmus Director of Corporate IP.


Cadmus’ overarching technical strategy and the architecture for this POC reflect our understanding of FPAC’s vision of a data-driven digital transformation mission. The POC itself provides easy and immediate access to a powerful combination and overlays of weather, crop, soil, NAIP imagery data from 2015 through 2019 available at their fingertips via data visualization tools with data exporting and sharing capabilities.
We consider this POC to be a minimum viable product for a much larger data pipeline solution that can be incrementally built to cater to FPAC’s custom needs. The technical architecture for this POC provides foundational technical components while retaining the flexibility to develop additional functionality.
“Cadmus’ architecture leverages a best-in-class technology stack, bringing all data to one platform with the ability to perform data governance and lay the foundation for developing advanced, powerful analytical and visualizations tools on top of assured quality of underlying data,” said Sarma Musty, Cadmus Data Architect.